* feat(channels): add DingTalk channel integration Add a new DingTalk messaging channel using the dingtalk-stream SDK with Stream Push (WebSocket), requiring no public IP. Supports both plain sampleMarkdown replies and optional AI Card streaming for a typewriter effect when card_template_id is configured. - Add DingTalkChannel implementation with token management, message routing, allowed_users filtering, and markdown adaptation - Register dingtalk in channel service registry and capability map - Propagate inbound metadata to outbound messages in ChannelManager for DingTalk sender context (sender_staff_id, conversation_type) - Add dingtalk-stream dependency to pyproject.toml - Add configuration examples in config.example.yaml and .env.example - Update all README translations with setup instructions - Add comprehensive test suite (test_dingtalk_channel.py) and metadata propagation test in test_channels.py - Update backend CLAUDE.md to document DingTalk channel Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * fix(channels): address PR review feedback for DingTalk integration - Replace runtime mutation of CHANNEL_CAPABILITIES with a `supports_streaming` property on the Channel base class, overridden by DingTalkChannel, FeishuChannel, and WeComChannel - Store stream client reference and attempt graceful disconnect in stop(); guard _on_chatbot_message with _running check to prevent post-stop message processing - Use msg.chat_id as the primary routing key in send/send_file via a shared _resolve_routing helper, with metadata as fallback - Fix process() return type annotation from tuple[str, str] to tuple[int, str] to match AckMessage.STATUS_OK - Protect _incoming_messages with threading.Lock for cross-thread safety between the Stream Push thread and the asyncio loop - Re-add Docker Compose URL guidance removed during DingTalk setup docs addition in README.md - Fix incomplete sentence in README_zh.md (missing verb "启用") Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * fix(docs): restore plain paragraph format for Docker Compose note Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * fix(channels): fix isinstance TypeError and add file size guard in DingTalk channel Use tuple syntax for isinstance() type check to avoid runtime TypeError with PEP 604 union types. Add upload size limit (20MB) before reading files into memory. Narrow exception handlers to specific types. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * fix(channels): propagate markdown fallback errors and validate access token response - Re-raise exceptions in _send_markdown_fallback to prevent partial deliveries (files sent without accompanying text) - Validate _get_access_token response: reject non-dict bodies, empty tokens, and coerce invalid expireIn to a safe default - Add tests for both fixes Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * fix(channels): validate upload response and broaden send_file exception handling - Validate _upload_media JSON response: handle JSONDecodeError and non-dict payloads gracefully by returning None - Broaden send_file exception tuple to include TypeError and AttributeError for unexpected JSON shapes Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * fix(channels): fix streaming race on channel registration and slim outbound metadata - Register channel in service before calling start() to avoid race where background receiver publishes inbound before registration, causing manager to fall back to static CHANNEL_CAPABILITIES - Strip known-large metadata keys (raw_message, ref_msg) from outbound messages to prevent memory bloat from propagated inbound payloads Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * Update service.py Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> * Update CLAUDE.md Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> --------- Co-authored-by: Claude Opus 4.6 <noreply@anthropic.com> Co-authored-by: Willem Jiang <willem.jiang@gmail.com> Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com>
34 KiB
🦌 DeerFlow - 2.0
English | 中文 | 日本語 | Français | Русский
![]()
2026年2月28日、バージョン2のリリースに伴い、DeerFlowはGitHub Trendingで🏆 第1位を獲得しました。素晴らしいコミュニティの皆さん、ありがとうございます!💪🔥
DeerFlow(Deep Exploration and Efficient Research Flow)は、サブエージェント、メモリ、サンドボックスを統合し、拡張可能なスキルによってあらゆるタスクを実行できるオープンソースのスーパーエージェントハーネスです。
https://github.com/user-attachments/assets/a8bcadc4-e040-4cf2-8fda-dd768b999c18
Note
DeerFlow 2.0はゼロからの完全な書き直しです。 v1とコードを共有していません。オリジナルのDeep Researchフレームワークをお探しの場合は、
1.xブランチで引き続きメンテナンスされています。現在の開発は2.0に移行しています。
公式ウェブサイト
実際のデモは公式ウェブサイトでご覧いただけます。
ByteDance Volcengine のコーディングプラン
- DeerFlowの実行には、Doubao-Seed-2.0-Code、DeepSeek v3.2、Kimi 2.5の使用を強く推奨します
- 詳細はこちら
- 中国大陸の開発者はこちらをクリック
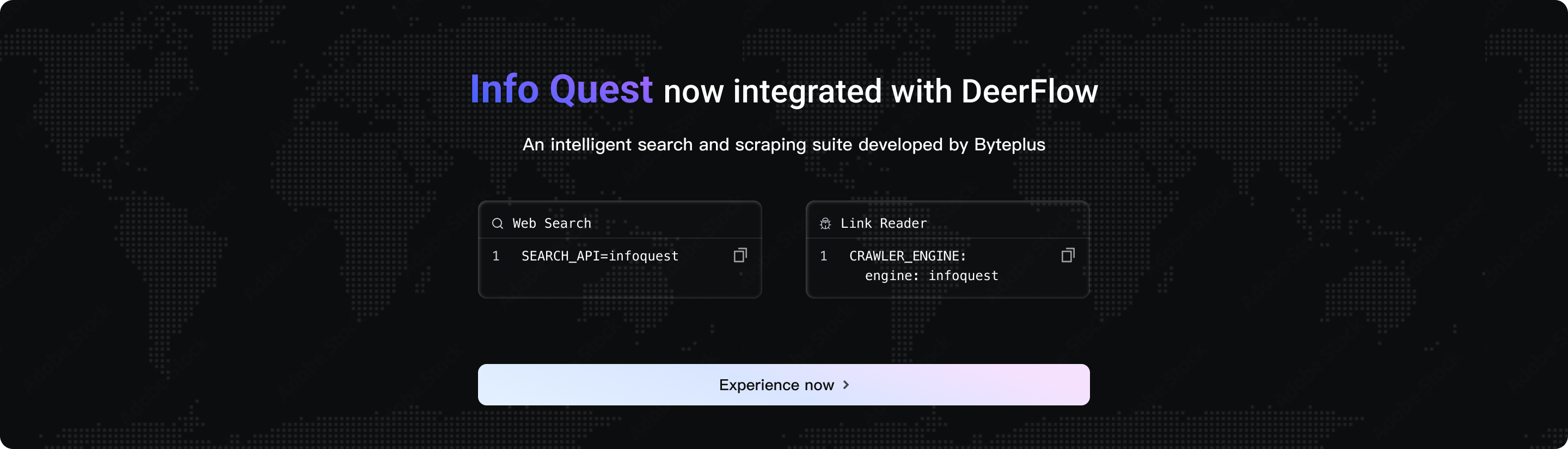
InfoQuest
DeerFlowは、BytePlusが独自に開発したインテリジェント検索・クローリングツールセット「InfoQuest(無料オンライン体験対応)」を新たに統合しました。
目次
- 🦌 DeerFlow - 2.0
Coding Agent に一文でセットアップを依頼
Claude Code、Codex、Cursor、Windsurf などの coding agent を使っているなら、次の一文をそのまま渡せます。
DeerFlow がまだ clone されていなければ先に clone してから、https://raw.githubusercontent.com/bytedance/deer-flow/main/Install.md に従ってローカル開発環境を初期化してください
このプロンプトは coding agent 向けです。必要なら先にリポジトリを clone し、Docker が使える場合は Docker を優先して初期セットアップを行い、最後に次の起動コマンドと不足している設定項目だけを返します。
クイックスタート
設定
-
DeerFlowリポジトリをクローン
git clone https://github.com/bytedance/deer-flow.git cd deer-flow -
ローカル設定ファイルの生成
プロジェクトルートディレクトリ(
deer-flow/)から以下を実行します:make configこのコマンドは、提供されたテンプレートに基づいてローカル設定ファイルを作成します。
-
使用するモデルの設定
config.yamlを編集し、少なくとも1つのモデルを定義します:models: - name: gpt-4 # 内部識別子 display_name: GPT-4 # 表示名 use: langchain_openai:ChatOpenAI # LangChainクラスパス model: gpt-4 # API用モデル識別子 api_key: $OPENAI_API_KEY # APIキー(推奨:環境変数を使用) max_tokens: 4096 # リクエストあたりの最大トークン数 temperature: 0.7 # サンプリング温度 - name: openrouter-gemini-2.5-flash display_name: Gemini 2.5 Flash (OpenRouter) use: langchain_openai:ChatOpenAI model: google/gemini-2.5-flash-preview api_key: $OPENAI_API_KEY # OpenRouterもここではOpenAI互換のフィールド名を使用 base_url: https://openrouter.ai/api/v1OpenRouterやOpenAI互換のゲートウェイは、
langchain_openai:ChatOpenAIとbase_urlで設定します。プロバイダー固有の環境変数名を使用したい場合は、api_keyでその変数を明示的に指定してください(例:api_key: $OPENROUTER_API_KEY)。 -
設定したモデルのAPIキーを設定
以下のいずれかの方法を選択してください:
-
オプションA:プロジェクトルートの
.envファイルを編集(推奨)TAVILY_API_KEY=your-tavily-api-key OPENAI_API_KEY=your-openai-api-key # OpenRouterもlangchain_openai:ChatOpenAI + base_url使用時はOPENAI_API_KEYを使用します。 # 必要に応じて他のプロバイダーキーを追加 INFOQUEST_API_KEY=your-infoquest-api-key -
オプションB:シェルで環境変数をエクスポート
export OPENAI_API_KEY=your-openai-api-key -
オプションC:
config.yamlを直接編集(本番環境には非推奨)models: - name: gpt-4 api_key: your-actual-api-key-here # プレースホルダーを置換
アプリケーションの実行
オプション1: Docker(推奨)
開発環境(ホットリロード、ソースマウント):
make docker-init # サンドボックスイメージをプル(初回またはイメージ更新時のみ)
make docker-start # サービスを開始(config.yamlからサンドボックスモードを自動検出)
make docker-startは、config.yamlがプロビジョナーモード(sandbox.use: deerflow.community.aio_sandbox:AioSandboxProviderとprovisioner_url)を使用している場合にのみprovisionerを起動します。
本番環境(ローカルでイメージをビルドし、ランタイム設定とデータをマウント):
make up # イメージをビルドして全本番サービスを開始
make down # コンテナを停止して削除
Note
LangGraphエージェントサーバーは現在
langgraph dev(オープンソースCLIサーバー)経由で実行されます。
アクセス: http://localhost:2026
詳細なDocker開発ガイドはCONTRIBUTING.mdをご覧ください。
オプション2: ローカル開発
サービスをローカルで実行する場合:
前提条件:上記の「設定」手順を先に完了してください(make configとモデルAPIキー)。make devには有効な設定ファイルが必要です(デフォルトはプロジェクトルートのconfig.yaml。DEER_FLOW_CONFIG_PATHで上書き可能)。
-
前提条件の確認:
make check # Node.js 22+、pnpm、uv、nginxを検証 -
依存関係のインストール:
make install # バックエンド+フロントエンドの依存関係をインストール -
(オプション)サンドボックスイメージの事前プル:
# Docker/コンテナベースのサンドボックス使用時に推奨 make setup-sandbox -
サービスの開始:
make dev -
アクセス: http://localhost:2026
詳細設定
サンドボックスモード
DeerFlowは複数のサンドボックス実行モードをサポートしています:
- ローカル実行(ホストマシン上で直接サンドボックスコードを実行)
- Docker実行(分離されたDockerコンテナ内でサンドボックスコードを実行)
- KubernetesによるDocker実行(プロビジョナーサービス経由でKubernetesポッドでサンドボックスコードを実行)
Docker開発では、サービスの起動はconfig.yamlのサンドボックスモードに従います。ローカル/Dockerモードではprovisionerは起動されません。
お好みのモードの設定についてはサンドボックス設定ガイドをご覧ください。
MCPサーバー
DeerFlowは、機能を拡張するための設定可能なMCPサーバーとスキルをサポートしています。
HTTP/SSE MCPサーバーでは、OAuthトークンフロー(client_credentials、refresh_token)がサポートされています。
詳細な手順はMCPサーバーガイドをご覧ください。
IMチャネル
DeerFlowはメッセージングアプリからのタスク受信をサポートしています。チャネルは設定時に自動的に開始されます。いずれもパブリックIPは不要です。
| チャネル | トランスポート | 難易度 |
|---|---|---|
| Telegram | Bot API(ロングポーリング) | 簡単 |
| Slack | Socket Mode | 中程度 |
| Feishu / Lark | WebSocket | 中程度 |
| DingTalk | Stream Push(WebSocket) | 中程度 |
config.yamlでの設定:
channels:
# LangGraphサーバーURL(デフォルト: http://localhost:2024)
langgraph_url: http://localhost:2024
# Gateway API URL(デフォルト: http://localhost:8001)
gateway_url: http://localhost:8001
# オプション: 全モバイルチャネルのグローバルセッションデフォルト
session:
assistant_id: lead_agent
config:
recursion_limit: 100
context:
thinking_enabled: true
is_plan_mode: false
subagent_enabled: false
feishu:
enabled: true
app_id: $FEISHU_APP_ID
app_secret: $FEISHU_APP_SECRET
# domain: https://open.feishu.cn # China (default)
# domain: https://open.larksuite.com # International
slack:
enabled: true
bot_token: $SLACK_BOT_TOKEN # xoxb-...
app_token: $SLACK_APP_TOKEN # xapp-...(Socket Mode)
allowed_users: [] # 空 = 全員許可
telegram:
enabled: true
bot_token: $TELEGRAM_BOT_TOKEN
allowed_users: [] # 空 = 全員許可
# オプション: チャネル/ユーザーごとのセッション設定
session:
assistant_id: mobile_agent
context:
thinking_enabled: false
users:
"123456789":
assistant_id: vip_agent
config:
recursion_limit: 150
context:
thinking_enabled: true
subagent_enabled: true
dingtalk:
enabled: true
client_id: $DINGTALK_CLIENT_ID # DingTalk Open PlatformのClientId
client_secret: $DINGTALK_CLIENT_SECRET # DingTalk Open PlatformのClientSecret
allowed_users: [] # 空 = 全員許可
card_template_id: "" # オプション:ストリーミングタイプライター効果用のAIカードテンプレートID
対応するAPIキーを.envファイルに設定します:
# Telegram
TELEGRAM_BOT_TOKEN=123456789:ABCdefGHIjklMNOpqrSTUvwxYZ
# Slack
SLACK_BOT_TOKEN=xoxb-...
SLACK_APP_TOKEN=xapp-...
# Feishu / Lark
FEISHU_APP_ID=cli_xxxx
FEISHU_APP_SECRET=your_app_secret
# DingTalk
DINGTALK_CLIENT_ID=your_client_id
DINGTALK_CLIENT_SECRET=your_client_secret
Telegramのセットアップ
- @BotFatherとチャットし、
/newbotを送信してHTTP APIトークンをコピーします。 .envにTELEGRAM_BOT_TOKENを設定し、config.yamlでチャネルを有効にします。
Slackのセットアップ
- api.slack.com/appsでSlackアプリを作成 → 新規アプリ作成 → 最初から作成。
- OAuth & Permissionsで、Botトークンスコープを追加:
app_mentions:read、chat:write、im:history、im:read、im:write、files:write。 - Socket Modeを有効化 →
connections:writeスコープのApp-Levelトークン(xapp-…)を生成。 - Event Subscriptionsで、ボットイベントを購読:
app_mention、message.im。 .envにSLACK_BOT_TOKENとSLACK_APP_TOKENを設定し、config.yamlでチャネルを有効にします。
Feishu / Larkのセットアップ
- Feishu Open Platformでアプリを作成 → ボット機能を有効化。
- 権限を追加:
im:message、im:message.p2p_msg:readonly、im:resource。 - イベントで
im.message.receive_v1を購読し、ロングコネクションモードを選択。 - App IDとApp Secretをコピー。
.envにFEISHU_APP_IDとFEISHU_APP_SECRETを設定し、config.yamlでチャネルを有効にします。
DingTalkのセットアップ
- DingTalk Open Platformでアプリを作成し、ロボット機能を有効化します。
- ロボット設定ページでメッセージ受信モードをStreamモードに設定します。
Client IDとClient Secretをコピー。.envにDINGTALK_CLIENT_IDとDINGTALK_CLIENT_SECRETを設定し、config.yamlでチャネルを有効にします。- (オプション) ストリーミングAIカード返信(タイプライター効果)を有効にするには、DingTalkカードプラットフォームでAIカードテンプレートを作成し、
config.yamlのcard_template_idにテンプレートIDを設定します。Card.Streaming.WriteおよびCard.Instance.Write権限の申請も必要です。
コマンド
チャネル接続後、チャットから直接DeerFlowと対話できます:
| コマンド | 説明 |
|---|---|
/new |
新しい会話を開始 |
/status |
現在のスレッド情報を表示 |
/models |
利用可能なモデルを一覧表示 |
/memory |
メモリを表示 |
/help |
ヘルプを表示 |
コマンドプレフィックスのないメッセージは通常のチャットとして扱われ、DeerFlowがスレッドを作成して会話形式で応答します。
LangSmithトレーシング
DeerFlowにはLangSmithによる可観測性が組み込まれています。有効にすると、すべてのLLM呼び出し、エージェント実行、ツール実行がトレースされ、LangSmithダッシュボードで確認できます。
.envファイルに以下を追加します:
LANGSMITH_TRACING=true
LANGSMITH_ENDPOINT=https://api.smith.langchain.com
LANGSMITH_API_KEY=lsv2_pt_xxxxxxxxxxxxxxxx
LANGSMITH_PROJECT=xxx
Dockerデプロイでは、トレーシングはデフォルトで無効です。.envでLANGSMITH_TRACING=trueとLANGSMITH_API_KEYを設定して有効にします。
Deep Researchからスーパーエージェントハーネスへ
DeerFlowはDeep Researchフレームワークとして始まり、コミュニティがそれを大きく発展させました。リリース以来、開発者たちはリサーチを超えて活用してきました:データパイプラインの構築、スライドデッキの生成、ダッシュボードの立ち上げ、コンテンツワークフローの自動化。私たちが予想もしなかったことです。
これは重要なことを示していました:DeerFlowは単なるリサーチツールではなかったのです。それはハーネス——エージェントが実際に仕事をこなすためのインフラを提供するランタイムでした。
そこで、ゼロから再構築しました。
DeerFlow 2.0は、もはやつなぎ合わせるフレームワークではありません。バッテリー同梱、完全に拡張可能なスーパーエージェントハーネスです。LangGraphとLangChainの上に構築され、エージェントが必要とするすべてを標準搭載しています:ファイルシステム、メモリ、スキル、サンドボックス実行、そして複雑なマルチステップタスクのためのプランニングとサブエージェントの生成機能。
そのまま使うもよし。分解して自分のものにするもよし。
コア機能
スキルとツール
スキルこそが、DeerFlowをほぼ何でもできるものにしています。
標準的なエージェントスキルは構造化された機能モジュールです——ワークフロー、ベストプラクティス、サポートリソースへの参照を定義するMarkdownファイルです。DeerFlowにはリサーチ、レポート生成、スライド作成、Webページ、画像・動画生成などの組み込みスキルが付属しています。しかし、真の力は拡張性にあります:独自のスキルを追加し、組み込みスキルを置き換え、複合ワークフローに組み合わせることができます。
スキルはプログレッシブに読み込まれます——タスクが必要とする時にのみ、一度にすべてではありません。これによりコンテキストウィンドウを軽量に保ち、トークンに敏感なモデルでもDeerFlowがうまく動作します。
Gateway経由で.skillアーカイブをインストールする際、DeerFlowはversion、author、compatibilityなどの標準的なオプショナルフロントマターメタデータを受け入れ、有効な外部スキルを拒否しません。
ツールも同じ哲学に従います。DeerFlowにはコアツールセット——Web検索、Webフェッチ、ファイル操作、bash実行——が付属し、MCPサーバーやPython関数によるカスタムツールをサポートしています。何でも入れ替え可能、何でも追加可能です。
Gatewayが生成するフォローアップ提案は、プレーン文字列のモデル出力とブロック/リスト形式のリッチコンテンツの両方をJSON配列レスポンスの解析前に正規化するため、プロバイダー固有のコンテンツラッパーが提案をサイレントにドロップすることはありません。
# サンドボックスコンテナ内のパス
/mnt/skills/public
├── research/SKILL.md
├── report-generation/SKILL.md
├── slide-creation/SKILL.md
├── web-page/SKILL.md
└── image-generation/SKILL.md
/mnt/skills/custom
└── your-custom-skill/SKILL.md ← あなたのカスタムスキル
Claude Code連携
claude-to-deerflowスキルを使えば、Claude Codeから直接、実行中のDeerFlowインスタンスと対話できます。リサーチタスクの送信、ステータスの確認、スレッドの管理——すべてターミナルから離れずに実行できます。
スキルのインストール:
npx skills add https://github.com/bytedance/deer-flow --skill claude-to-deerflow
DeerFlowが実行中であることを確認し(デフォルトはhttp://localhost:2026)、Claude Codeで/claude-to-deerflowコマンドを使用します。
できること:
- DeerFlowにメッセージを送信してストリーミングレスポンスを取得
- 実行モードの選択:flash(高速)、standard、pro(プランニング)、ultra(サブエージェント)
- DeerFlowのヘルスチェック、モデル/スキル/エージェントの一覧表示
- スレッドと会話履歴の管理
- 分析用ファイルのアップロード
環境変数(オプション、カスタムエンドポイント用):
DEERFLOW_URL=http://localhost:2026 # 統合プロキシベースURL
DEERFLOW_GATEWAY_URL=http://localhost:2026 # Gateway API
DEERFLOW_LANGGRAPH_URL=http://localhost:2026/api/langgraph # LangGraph API
完全なAPIリファレンスはskills/public/claude-to-deerflow/SKILL.mdをご覧ください。
サブエージェント
複雑なタスクは単一のパスに収まりません。DeerFlowはそれを分解します。
リードエージェントはオンザフライでサブエージェントを生成できます——それぞれ独自のスコープ付きコンテキスト、ツール、終了条件を持ちます。サブエージェントは可能な限り並列で実行され、構造化された結果を報告し、リードエージェントがすべてを一貫した出力に統合します。
これがDeerFlowが数分から数時間かかるタスクを処理する方法です:リサーチタスクが十数のサブエージェントに展開され、それぞれが異なる角度を探索し、1つのレポート——またはWebサイト——または生成されたビジュアル付きのスライドデッキに収束します。1つのハーネス、多くの手。
サンドボックスとファイルシステム
DeerFlowは物事を語るだけではありません。自分のコンピューターを持っています。
各タスクは、完全なファイルシステムを持つ分離されたDockerコンテナ内で実行されます——スキル、ワークスペース、アップロード、出力。エージェントはファイルの読み書き・編集を行います。bashコマンドを実行し、コーディングを行います。画像を表示します。すべてサンドボックス化され、すべて監査可能で、セッション間の汚染はゼロです。
これが、ツールアクセスのあるチャットボットと、実際の実行環境を持つエージェントの違いです。
# サンドボックスコンテナ内のパス
/mnt/user-data/
├── uploads/ ← あなたのファイル
├── workspace/ ← エージェントの作業ディレクトリ
└── outputs/ ← 最終成果物
コンテキストエンジニアリング
分離されたサブエージェントコンテキスト:各サブエージェントは独自の分離されたコンテキストで実行されます。これにより、サブエージェントはメインエージェントや他のサブエージェントのコンテキストを見ることができません。これは、サブエージェントが目の前のタスクに集中し、メインエージェントや他のサブエージェントのコンテキストに気を取られないようにするために重要です。
要約化:セッション内で、DeerFlowはコンテキストを積極的に管理します——完了したサブタスクの要約、中間結果のファイルシステムへのオフロード、もはや直接関係のないものの圧縮。これにより、コンテキストウィンドウを超えることなく、長いマルチステップタスク全体を通じてシャープさを維持します。
長期メモリ
ほとんどのエージェントは、会話が終わるとすべてを忘れます。DeerFlowは記憶します。
セッションをまたいで、DeerFlowはあなたのプロフィール、好み、蓄積された知識の永続的なメモリを構築します。使えば使うほど、あなたのことをよく知るようになります——あなたの文体、技術スタック、繰り返されるワークフロー。メモリはローカルに保存され、あなたの管理下にあります。
メモリ更新は適用時に重複するファクトエントリをスキップするようになり、繰り返される好みやコンテキストがセッションをまたいで際限なく蓄積されることはありません。
推奨モデル
DeerFlowはモデルに依存しません——OpenAI互換APIを実装する任意のLLMで動作します。とはいえ、以下をサポートするモデルで最高のパフォーマンスを発揮します:
- 長いコンテキストウィンドウ(10万トークン以上):深いリサーチとマルチステップタスク向け
- 推論能力:適応的なプランニングと複雑な分解向け
- マルチモーダル入力:画像理解と動画理解向け
- 強力なツール使用:信頼性の高いファンクションコーリングと構造化された出力向け
組み込みPythonクライアント
DeerFlowは、完全なHTTPサービスを実行せずに組み込みPythonライブラリとして使用できます。DeerFlowClientは、すべてのエージェントとGateway機能へのプロセス内直接アクセスを提供し、HTTP Gateway APIと同じレスポンススキーマを返します:
from deerflow.client import DeerFlowClient
client = DeerFlowClient()
# チャット
response = client.chat("Analyze this paper for me", thread_id="my-thread")
# ストリーミング(LangGraph SSEプロトコル:values、messages-tuple、end)
for event in client.stream("hello"):
if event.type == "messages-tuple" and event.data.get("type") == "ai":
print(event.data["content"])
# 設定&管理 — Gateway準拠のdictを返す
models = client.list_models() # {"models": [...]}
skills = client.list_skills() # {"skills": [...]}
client.update_skill("web-search", enabled=True)
client.upload_files("thread-1", ["./report.pdf"]) # {"success": True, "files": [...]}
すべてのdict返却メソッドはCIでGateway Pydanticレスポンスモデルに対して検証されており(TestGatewayConformance)、組み込みクライアントがHTTP APIスキーマと同期していることを保証します。完全なAPIドキュメントはbackend/packages/harness/deerflow/client.pyをご覧ください。
ドキュメント
- コントリビュートガイド - 開発環境のセットアップとワークフロー
- 設定ガイド - セットアップと設定の手順
- アーキテクチャ概要 - 技術的なアーキテクチャの詳細
- バックエンドアーキテクチャ - バックエンドアーキテクチャとAPIリファレンス
⚠️ セキュリティに関する注意
不適切なデプロイはセキュリティリスクを引き起こす可能性があります
DeerFlowはシステムコマンドの実行、リソース操作、ビジネスロジックの呼び出しなどの重要な高権限機能を備えており、デフォルトではローカルの信頼できる環境(127.0.0.1のループバックアクセスのみ)にデプロイされる設計になっています。信頼できないLAN、公開クラウドサーバー、または複数のエンドポイントからアクセス可能なネットワーク環境にエージェントをデプロイし、厳格なセキュリティ対策を講じない場合、以下のようなセキュリティリスクが生じる可能性があります:
- 不正な違法呼び出し:エージェントの機能が権限のない第三者や悪意のあるインターネットスキャナーに発見され、システムコマンドやファイル読み書きなどの高リスク操作を実行する不正な一括リクエストが引き起こされ、重大なセキュリティ上の問題が発生する可能性があります。
- コンプライアンスおよび法的リスク:エージェントがサイバー攻撃やデータ窃取などの違法行為に不正使用された場合、法的責任やコンプライアンス上のリスクが生じる可能性があります。
セキュリティ推奨事項
注意:DeerFlowはローカルの信頼できるネットワーク環境にデプロイすることを強く推奨します。 クロスデバイス・クロスネットワークのデプロイが必要な場合は、以下のような厳格なセキュリティ対策を実装する必要があります:
- IPホワイトリストの設定:
iptablesを使用するか、ハードウェアファイアウォール / ACL機能付きスイッチをデプロイしてIPホワイトリストルールを設定し、他のすべてのIPアドレスからのアクセスを拒否します。 - 前置認証:リバースプロキシ(nginxなど)を設定し、強力な前置認証を有効化して、認証なしのアクセスをブロックします。
- ネットワーク分離:可能であれば、エージェントと信頼できるデバイスを同一の専用VLANに配置し、他のネットワークデバイスから隔離します。
- アップデートを継続的に確認:DeerFlowのセキュリティ機能のアップデートを継続的にフォローしてください。
コントリビュート
コントリビューションを歓迎します!開発環境のセットアップ、ワークフロー、ガイドラインについてはCONTRIBUTING.mdをご覧ください。
回帰テストのカバレッジには、backend/tests/でのDockerサンドボックスモード検出とプロビジョナーkubeconfig-pathハンドリングテストが含まれます。
ライセンス
このプロジェクトはオープンソースであり、MITライセンスの下で提供されています。
謝辞
DeerFlowはオープンソースコミュニティの素晴らしい成果の上に構築されています。DeerFlowを可能にしてくれたすべてのプロジェクトとコントリビューターに深く感謝いたします。まさに、巨人の肩の上に立っています。
以下のプロジェクトの貴重な貢献に心からの感謝を申し上げます:
- LangChain:その優れたフレームワークがLLMのインタラクションとチェーンを支え、シームレスな統合と機能を実現しています。
- LangGraph:マルチエージェントオーケストレーションへの革新的なアプローチが、DeerFlowの洗練されたワークフローの実現に大きく貢献しています。
これらのプロジェクトはオープンソースコラボレーションの変革的な力を体現しており、その基盤の上に構築できることを誇りに思います。
主要コントリビューター
DeerFlowのコア著者に心からの感謝を捧げます。そのビジョン、情熱、献身がこのプロジェクトに命を吹き込みました:
揺るぎないコミットメントと専門知識が、DeerFlowの成功の原動力です。この旅の先頭に立ってくださっていることを光栄に思います。