* feat(auth): introduce backend auth module Port RFC-001 authentication core from PR #1728: - JWT token handling (create_access_token, decode_token, TokenPayload) - Password hashing (bcrypt) with verify_password - SQLite UserRepository with base interface - Provider Factory pattern (LocalAuthProvider) - CLI reset_admin tool - Auth-specific errors (AuthErrorCode, TokenError, AuthErrorResponse) Deps: - bcrypt>=4.0.0 - pyjwt>=2.9.0 - email-validator>=2.0.0 - backend/uv.toml pins public PyPI index Tests: 12 pure unit tests (test_auth_config.py, test_auth_errors.py). Scope note: authz.py, test_auth.py, and test_auth_type_system.py are deferred to commit 2 because they depend on middleware and deps wiring that is not yet in place. Commit 1 stays "pure new files only" as the spec mandates. * feat(auth): wire auth end-to-end (middleware + frontend replacement) Backend: - Port auth_middleware, csrf_middleware, langgraph_auth, routers/auth - Port authz decorator (owner_filter_key defaults to 'owner_id') - Merge app.py: register AuthMiddleware + CSRFMiddleware + CORS, add _ensure_admin_user lifespan hook, _migrate_orphaned_threads helper, register auth router - Merge deps.py: add get_local_provider, get_current_user_from_request, get_optional_user_from_request; keep get_current_user as thin str|None adapter for feedback router - langgraph.json: add auth path pointing to langgraph_auth.py:auth - Rename metadata['user_id'] -> metadata['owner_id'] in langgraph_auth (both metadata write and LangGraph filter dict) + test fixtures Frontend: - Delete better-auth library and api catch-all route - Remove better-auth npm dependency and env vars (BETTER_AUTH_SECRET, BETTER_AUTH_GITHUB_*) from env.js - Port frontend/src/core/auth/* (AuthProvider, gateway-config, proxy-policy, server-side getServerSideUser, types) - Port frontend/src/core/api/fetcher.ts - Port (auth)/layout, (auth)/login, (auth)/setup pages - Rewrite workspace/layout.tsx as server component that calls getServerSideUser and wraps in AuthProvider - Port workspace/workspace-content.tsx for the client-side sidebar logic Tests: - Port 5 auth test files (test_auth, test_auth_middleware, test_auth_type_system, test_ensure_admin, test_langgraph_auth) - 176 auth tests PASS After this commit: login/logout/registration flow works, but persistence layer does not yet filter by owner_id. Commit 4 closes that gap. * feat(auth): account settings page + i18n - Port account-settings-page.tsx (change password, change email, logout) - Wire into settings-dialog.tsx as new "account" section with UserIcon, rendered first in the section list - Add i18n keys: - en-US/zh-CN: settings.sections.account ("Account" / "账号") - en-US/zh-CN: button.logout ("Log out" / "退出登录") - types.ts: matching type declarations * feat(auth): enforce owner_id across 2.0-rc persistence layer Add request-scoped contextvar-based owner filtering to threads_meta, runs, run_events, and feedback repositories. Router code is unchanged — isolation is enforced at the storage layer so that any caller that forgets to pass owner_id still gets filtered results, and new routes cannot accidentally leak data. Core infrastructure ------------------- - deerflow/runtime/user_context.py (new): - ContextVar[CurrentUser | None] with default None - runtime_checkable CurrentUser Protocol (structural subtype with .id) - set/reset/get/require helpers - AUTO sentinel + resolve_owner_id(value, method_name) for sentinel three-state resolution: AUTO reads contextvar, explicit str overrides, explicit None bypasses the filter (for migration/CLI) Repository changes ------------------ - ThreadMetaRepository: create/get/search/update_*/delete gain owner_id=AUTO kwarg; read paths filter by owner, writes stamp it, mutations check ownership before applying - RunRepository: put/get/list_by_thread/delete gain owner_id=AUTO kwarg - FeedbackRepository: create/get/list_by_run/list_by_thread/delete gain owner_id=AUTO kwarg - DbRunEventStore: list_messages/list_events/list_messages_by_run/ count_messages/delete_by_thread/delete_by_run gain owner_id=AUTO kwarg. Write paths (put/put_batch) read contextvar softly: when a request-scoped user is available, owner_id is stamped; background worker writes without a user context pass None which is valid (orphan row to be bound by migration) Schema ------ - persistence/models/run_event.py: RunEventRow.owner_id = Mapped[ str | None] = mapped_column(String(64), nullable=True, index=True) - No alembic migration needed: 2.0 ships fresh, Base.metadata.create_all picks up the new column automatically Middleware ---------- - auth_middleware.py: after cookie check, call get_optional_user_from_ request to load the real User, stamp it into request.state.user AND the contextvar via set_current_user, reset in a try/finally. Public paths and unauthenticated requests continue without contextvar, and @require_auth handles the strict 401 path Test infrastructure ------------------- - tests/conftest.py: @pytest.fixture(autouse=True) _auto_user_context sets a default SimpleNamespace(id="test-user-autouse") on every test unless marked @pytest.mark.no_auto_user. Keeps existing 20+ persistence tests passing without modification - pyproject.toml [tool.pytest.ini_options]: register no_auto_user marker so pytest does not emit warnings for opt-out tests - tests/test_user_context.py: 6 tests covering three-state semantics, Protocol duck typing, and require/optional APIs - tests/test_thread_meta_repo.py: one test updated to pass owner_id= None explicitly where it was previously relying on the old default Test results ------------ - test_user_context.py: 6 passed - test_auth*.py + test_langgraph_auth.py + test_ensure_admin.py: 127 - test_run_event_store / test_run_repository / test_thread_meta_repo / test_feedback: 92 passed - Full backend suite: 1905 passed, 2 failed (both @requires_llm flaky integration tests unrelated to auth), 1 skipped * feat(auth): extend orphan migration to 2.0-rc persistence tables _ensure_admin_user now runs a three-step pipeline on every boot: Step 1 (fatal): admin user exists / is created / password is reset Step 2 (non-fatal): LangGraph store orphan threads → admin Step 3 (non-fatal): SQL persistence tables → admin - threads_meta - runs - run_events - feedback Each step is idempotent. The fatal/non-fatal split mirrors PR #1728's original philosophy: admin creation failure blocks startup (the system is unusable without an admin), whereas migration failures log a warning and let the service proceed (a partial migration is recoverable; a missing admin is not). Key helpers ----------- - _iter_store_items(store, namespace, *, page_size=500): async generator that cursor-paginates across LangGraph store pages. Fixes PR #1728's hardcoded limit=1000 bug that would silently lose orphans beyond the first page. - _migrate_orphaned_threads(store, admin_user_id): Rewritten to use _iter_store_items. Returns the migrated count so the caller can log it; raises only on unhandled exceptions. - _migrate_orphan_sql_tables(admin_user_id): Imports the 4 ORM models lazily, grabs the shared session factory, runs one UPDATE per table in a single transaction, commits once. No-op when no persistence backend is configured (in-memory dev). Tests: test_ensure_admin.py (8 passed) * test(auth): port AUTH test plan docs + lint/format pass - Port backend/docs/AUTH_TEST_PLAN.md and AUTH_UPGRADE.md from PR #1728 - Rename metadata.user_id → metadata.owner_id in AUTH_TEST_PLAN.md (4 occurrences from the original PR doc) - ruff auto-fix UP037 in sentinel type annotations: drop quotes around "str | None | _AutoSentinel" now that from __future__ import annotations makes them implicit string forms - ruff format: 2 files (app/gateway/app.py, runtime/user_context.py) Note on test coverage additions: - conftest.py autouse fixture was already added in commit 4 (had to be co-located with the repository changes to keep pre-existing persistence tests passing) - cross-user isolation E2E tests (test_owner_isolation.py) deferred — enforcement is already proven by the 98-test repository suite via the autouse fixture + explicit _AUTO sentinel exercises - New test cases (TC-API-17..20, TC-ATK-13, TC-MIG-01..07) listed in AUTH_TEST_PLAN.md are deferred to a follow-up PR — they are manual-QA test cases rather than pytest code, and the spec-level coverage is already met by test_user_context.py + the 98-test repository suite. Final test results: - Auth suite (test_auth*, test_langgraph_auth, test_ensure_admin, test_user_context): 186 passed - Persistence suite (test_run_event_store, test_run_repository, test_thread_meta_repo, test_feedback): 98 passed - Lint: ruff check + ruff format both clean * test(auth): add cross-user isolation test suite 10 tests exercising the storage-layer owner filter by manually switching the user_context contextvar between two users. Verifies the safety invariant: After a repository write with owner_id=A, a subsequent read with owner_id=B must not return the row, and vice versa. Covers all 4 tables that own user-scoped data: TC-API-17 threads_meta — read, search, update, delete cross-user TC-API-18 runs — get, list_by_thread, delete cross-user TC-API-19 run_events — list_messages, list_events, count_messages, delete_by_thread (CRITICAL: raw conversation content leak vector) TC-API-20 feedback — get, list_by_run, delete cross-user Plus two meta-tests verifying the sentinel pattern itself: - AUTO + unset contextvar raises RuntimeError - explicit owner_id=None bypasses the filter (migration escape hatch) Architecture note ----------------- These tests bypass the HTTP layer by design. The full chain (cookie → middleware → contextvar → repository) is covered piecewise: - test_auth_middleware.py: middleware sets contextvar from cookies - test_owner_isolation.py: repositories enforce isolation when contextvar is set to different users Together they prove the end-to-end safety property without the ceremony of spinning up a full TestClient + in-memory DB for every router endpoint. Tests pass: 231 (full auth + persistence + isolation suite) Lint: clean * refactor(auth): migrate user repository to SQLAlchemy ORM Move the users table into the shared persistence engine so auth matches the pattern of threads_meta, runs, run_events, and feedback — one engine, one session factory, one schema init codepath. New files --------- - persistence/user/__init__.py, persistence/user/model.py: UserRow ORM class with partial unique index on (oauth_provider, oauth_id) - Registered in persistence/models/__init__.py so Base.metadata.create_all() picks it up Modified -------- - auth/repositories/sqlite.py: rewritten as async SQLAlchemy, identical constructor pattern to the other four repositories (def __init__(self, session_factory) + self._sf = session_factory) - auth/config.py: drop users_db_path field — storage is configured through config.database like every other table - deps.py/get_local_provider: construct SQLiteUserRepository with the shared session factory, fail fast if engine is not initialised - tests/test_auth.py: rewrite test_sqlite_round_trip_new_fields to use the shared engine (init_engine + close_engine in a tempdir) - tests/test_auth_type_system.py: add per-test autouse fixture that spins up a scratch engine and resets deps._cached_* singletons * refactor(auth): remove SQL orphan migration (unused in supported scenarios) The _migrate_orphan_sql_tables helper existed to bind NULL owner_id rows in threads_meta, runs, run_events, and feedback to the admin on first boot. But in every supported upgrade path, it's a no-op: 1. Fresh install: create_all builds fresh tables, no legacy rows 2. No-auth → with-auth (no existing persistence DB): persistence tables are created fresh by create_all, no legacy rows 3. No-auth → with-auth (has existing persistence DB from #1930): NOT a supported upgrade path — "有 DB 到有 DB" schema evolution is out of scope; users wipe DB or run manual ALTER So the SQL orphan migration never has anything to do in the supported matrix. Delete the function, simplify _ensure_admin_user from a 3-step pipeline to a 2-step one (admin creation + LangGraph store orphan migration only). LangGraph store orphan migration stays: it serves the real "no-auth → with-auth" upgrade path where a user's existing LangGraph thread metadata has no owner_id field and needs to be stamped with the newly-created admin's id. Tests: 284 passed (auth + persistence + isolation) Lint: clean * security(auth): write initial admin password to 0600 file instead of logs CodeQL py/clear-text-logging-sensitive-data flagged 3 call sites that logged the auto-generated admin password to stdout via logger.info(). Production log aggregators (ELK/Splunk/etc) would have captured those cleartext secrets. Replace with a shared helper that writes to .deer-flow/admin_initial_credentials.txt with mode 0600, and log only the path. New file -------- - app/gateway/auth/credential_file.py: write_initial_credentials() helper. Takes email, password, and a "initial"/"reset" label. Creates .deer-flow/ if missing, writes a header comment plus the email+password, chmods 0o600, returns the absolute Path. Modified -------- - app/gateway/app.py: both _ensure_admin_user paths (fresh creation + needs_setup password reset) now write to file and log the path - app/gateway/auth/reset_admin.py: rewritten to use the shared ORM repo (SQLiteUserRepository with session_factory) and the credential_file helper. The previous implementation was broken after the earlier ORM refactor — it still imported _get_users_conn and constructed SQLiteUserRepository() without a session factory. No tests changed — the three password-log sites are all exercised via existing test_ensure_admin.py which checks that startup succeeds, not that a specific string appears in logs. CodeQL alerts 272, 283, 284: all resolved. * security(auth): strict JWT validation in middleware (fix junk cookie bypass) AUTH_TEST_PLAN test 7.5.8 expects junk cookies to be rejected with 401. The previous middleware behaviour was "presence-only": check that some access_token cookie exists, then pass through. In combination with my Task-12 decision to skip @require_auth decorators on routes, this created a gap where a request with any cookie-shaped string (e.g. access_token=not-a-jwt) would bypass authentication on routes that do not touch the repository (/api/models, /api/mcp/config, /api/memory, /api/skills, …). Fix: middleware now calls get_current_user_from_request() strictly and catches the resulting HTTPException to render a 401 with the proper fine-grained error code (token_invalid, token_expired, user_not_found, …). On success it stamps request.state.user and the contextvar so repository-layer owner filters work downstream. The 4 old "_with_cookie_passes" tests in test_auth_middleware.py were written for the presence-only behaviour; they asserted that a junk cookie would make the handler return 200. They are renamed to "_with_junk_cookie_rejected" and their assertions flipped to 401. The negative path (no cookie → 401 not_authenticated) is unchanged. Verified: no cookie → 401 not_authenticated junk cookie → 401 token_invalid (the fixed bug) expired cookie → 401 token_expired Tests: 284 passed (auth + persistence + isolation) Lint: clean * security(auth): wire @require_permission(owner_check=True) on isolation routes Apply the require_permission decorator to all 28 routes that take a {thread_id} path parameter. Combined with the strict middleware (previous commit), this gives the double-layer protection that AUTH_TEST_PLAN test 7.5.9 documents: Layer 1 (AuthMiddleware): cookie + JWT validation, rejects junk cookies and stamps request.state.user Layer 2 (@require_permission with owner_check=True): per-resource ownership verification via ThreadMetaStore.check_access — returns 404 if a different user owns the thread The decorator's owner_check branch is rewritten to use the SQL thread_meta_repo (the 2.0-rc persistence layer) instead of the LangGraph store path that PR #1728 used (_store_get / get_store in routers/threads.py). The inject_record convenience is dropped — no caller in 2.0 needs the LangGraph blob, and the SQL repo has a different shape. Routes decorated (28 total): - threads.py: delete, patch, get, get-state, post-state, post-history - thread_runs.py: post-runs, post-runs-stream, post-runs-wait, list_runs, get_run, cancel_run, join_run, stream_existing_run, list_thread_messages, list_run_messages, list_run_events, thread_token_usage - feedback.py: create, list, stats, delete - uploads.py: upload (added Request param), list, delete - artifacts.py: get_artifact - suggestions.py: generate (renamed body parameter to avoid conflict with FastAPI Request) Test fixes: - test_suggestions_router.py: bypass the decorator via __wrapped__ (the unit tests cover parsing logic, not auth — no point spinning up a thread_meta_repo just to test JSON unwrapping) - test_auth_middleware.py 4 fake-cookie tests: already updated in the previous commit (745bf432) Tests: 293 passed (auth + persistence + isolation + suggestions) Lint: clean * security(auth): defense-in-depth fixes from release validation pass Eight findings caught while running the AUTH_TEST_PLAN end-to-end against the deployed sg_dev stack. Each is a pre-condition for shipping release/2.0-rc that the previous PRs missed. Backend hardening - routers/auth.py: rate limiter X-Real-IP now requires AUTH_TRUSTED_PROXIES whitelist (CIDR/IP allowlist). Without nginx in front, the previous code honored arbitrary X-Real-IP, letting an attacker rotate the header to fully bypass the per-IP login lockout. - routers/auth.py: 36-entry common-password blocklist via Pydantic field_validator on RegisterRequest + ChangePasswordRequest. The shared _validate_strong_password helper keeps the constraint in one place. - routers/threads.py: ThreadCreateRequest + ThreadPatchRequest strip server-reserved metadata keys (owner_id, user_id) via Pydantic field_validator so a forged value can never round-trip back to other clients reading the same thread. The actual ownership invariant stays on the threads_meta row; this closes the metadata-blob echo gap. - authz.py + thread_meta/sql.py: require_permission gains a require_existing flag plumbed through check_access(require_existing=True). Destructive routes (DELETE/PATCH/state-update/runs/feedback) now treat a missing thread_meta row as 404 instead of "untracked legacy thread, allow", closing the cross-user delete-idempotence gap where any user could successfully DELETE another user's deleted thread. - repositories/sqlite.py + base.py: update_user raises UserNotFoundError on a vanished row instead of silently returning the input. Concurrent delete during password reset can no longer look like a successful update. - runtime/user_context.py: resolve_owner_id() coerces User.id (UUID) to str at the contextvar boundary so SQLAlchemy String(64) columns can bind it. The whole 2.0-rc isolation pipeline was previously broken end-to-end (POST /api/threads → 500 "type 'UUID' is not supported"). - persistence/engine.py: SQLAlchemy listener enables PRAGMA journal_mode=WAL, synchronous=NORMAL, foreign_keys=ON on every new SQLite connection. TC-UPG-06 in the test plan expects WAL; previous code shipped with the default 'delete' journal. - auth_middleware.py: stamp request.state.auth = AuthContext(...) so @require_permission's short-circuit fires; previously every isolation request did a duplicate JWT decode + users SELECT. Also unifies the 401 payload through AuthErrorResponse(...).model_dump(). - app.py: _ensure_admin_user restructure removes the noqa F821 scoping bug where 'password' was referenced outside the branch that defined it. New _announce_credentials helper absorbs the duplicate log block in the fresh-admin and reset-admin branches. * fix(frontend+nginx): rollout CSRF on every state-changing client path The frontend was 100% broken in gateway-pro mode for any user trying to open a specific chat thread. Three cumulative bugs each silently masked the next. LangGraph SDK CSRF gap (api-client.ts) - The Client constructor took only apiUrl, no defaultHeaders, no fetch interceptor. The SDK's internal fetch never sent X-CSRF-Token, so every state-changing /api/langgraph-compat/* call (runs/stream, threads/search, threads/{tid}/history, ...) hit CSRFMiddleware and got 403 before reaching the auth check. UI symptom: empty thread page with no error message; the SPA's hooks swallowed the rejection. - Fix: pass an onRequest hook that injects X-CSRF-Token from the csrf_token cookie per request. Reading the cookie per call (not at construction time) handles login / logout / password-change cookie rotation transparently. The SDK's prepareFetchOptions calls onRequest for both regular requests AND streaming/SSE/reconnect, so the same hook covers runs.stream and runs.joinStream. Raw fetch CSRF gap (7 files) - Audit: 11 frontend fetch sites, only 2 included CSRF (login/setup + account-settings change-password). The other 7 routed through raw fetch() with no header — suggestions, memory, agents, mcp, skills, uploads, and the local thread cleanup hook all 403'd silently. - Fix: enhance fetcher.ts:fetchWithAuth to auto-inject X-CSRF-Token on POST/PUT/DELETE/PATCH from a single shared readCsrfCookie() helper. Convert all 7 raw fetch() callers to fetchWithAuth so the contract is centrally enforced. api-client.ts and fetcher.ts share readCsrfCookie + STATE_CHANGING_METHODS to avoid drift. nginx routing + buffering (nginx.local.conf) - The auth feature shipped without updating the nginx config: per-API explicit location blocks but no /api/v1/auth/, /api/feedback, /api/runs. The frontend's client-side fetches to /api/v1/auth/login/local 404'd from the Next.js side because nginx routed /api/* to the frontend. - Fix: add catch-all `location /api/` that proxies to the gateway. nginx longest-prefix matching keeps the explicit blocks (/api/models, /api/threads regex, /api/langgraph/, ...) winning for their paths. - Fix: disable proxy_buffering + proxy_request_buffering for the frontend `location /` block. Without it, nginx tries to spool large Next.js chunks into /var/lib/nginx/proxy (root-owned) and fails with Permission denied → ERR_INCOMPLETE_CHUNKED_ENCODING → ChunkLoadError. * test(auth): release-validation test infra and new coverage Test fixtures and unit tests added during the validation pass. Router test helpers (NEW: tests/_router_auth_helpers.py) - make_authed_test_app(): builds a FastAPI test app with a stub middleware that stamps request.state.user + request.state.auth and a permissive thread_meta_repo mock. TestClient-based router tests (test_artifacts_router, test_threads_router) use it instead of bare FastAPI() so the new @require_permission(owner_check=True) decorators short-circuit cleanly. - call_unwrapped(): walks the __wrapped__ chain to invoke the underlying handler without going through the authz wrappers. Direct-call tests (test_uploads_router) use it. Typed with ParamSpec so the wrapped signature flows through. Backend test additions - test_auth.py: 7 tests for the new _get_client_ip trust model (no proxy / trusted proxy / untrusted peer / XFF rejection / invalid CIDR / no client). 5 tests for the password blocklist (literal, case-insensitive, strong password accepted, change-password binding, short-password length-check still fires before blocklist). test_update_user_raises_when_row_concurrently_deleted: closes a shipped-without-coverage gap on the new UserNotFoundError contract. - test_thread_meta_repo.py: 4 tests for check_access(require_existing=True) — strict missing-row denial, strict owner match, strict owner mismatch, strict null-owner still allowed (shared rows survive the tightening). - test_ensure_admin.py: 3 tests for _migrate_orphaned_threads / _iter_store_items pagination, covering the TC-UPG-02 upgrade story end-to-end via mock store. Closes the gap where the cursor pagination was untested even though the previous PR rewrote it. - test_threads_router.py: 5 tests for _strip_reserved_metadata (owner_id removal, user_id removal, safe-keys passthrough, empty input, both-stripped). - test_auth_type_system.py: replace "password123" fixtures with Tr0ub4dor3a / AnotherStr0ngPwd! so the new password blocklist doesn't reject the test data. * docs(auth): refresh TC-DOCKER-05 + document Docker validation gap - AUTH_TEST_PLAN.md TC-DOCKER-05: the previous expectation ("admin password visible in docker logs") was stale after the simplify pass that moved credentials to a 0600 file. The grep "Password:" check would have silently failed and given a false sense of coverage. New expectation matches the actual file-based path: 0600 file in DEER_FLOW_HOME, log shows the path (not the secret), reverse-grep asserts no leaked password in container logs. - NEW: docs/AUTH_TEST_DOCKER_GAP.md documents the only un-executed block in the test plan (TC-DOCKER-01..06). Reason: sg_dev validation host has no Docker daemon installed. The doc maps each Docker case to an already-validated bare-metal equivalent (TC-1.1, TC-REENT-01, TC-API-02 etc.) so the gap is auditable, and includes pre-flight reproduction steps for whoever has Docker available. --------- Co-authored-by: greatmengqi <chenmengqi.0376@bytedance.com>
🦌 DeerFlow - 2.0
English | 中文 | 日本語 | Français | Русский
![]()
On February 28th, 2026, DeerFlow claimed the 🏆 #1 spot on GitHub Trending following the launch of version 2. Thanks a million to our incredible community — you made this happen! 💪🔥
DeerFlow (Deep Exploration and Efficient Research Flow) is an open-source super agent harness that orchestrates sub-agents, memory, and sandboxes to do almost anything — powered by extensible skills.
https://github.com/user-attachments/assets/a8bcadc4-e040-4cf2-8fda-dd768b999c18
Note
DeerFlow 2.0 is a ground-up rewrite. It shares no code with v1. If you're looking for the original Deep Research framework, it's maintained on the
1.xbranch — contributions there are still welcome. Active development has moved to 2.0.
Official Website
Learn more and see real demos on our official website.
Coding Plan from ByteDance Volcengine
- We strongly recommend using Doubao-Seed-2.0-Code, DeepSeek v3.2 and Kimi 2.5 to run DeerFlow
- Learn more
- 中国大陆地区的开发者请点击这里
InfoQuest
DeerFlow has newly integrated the intelligent search and crawling toolset independently developed by BytePlus--InfoQuest (supports free online experience)
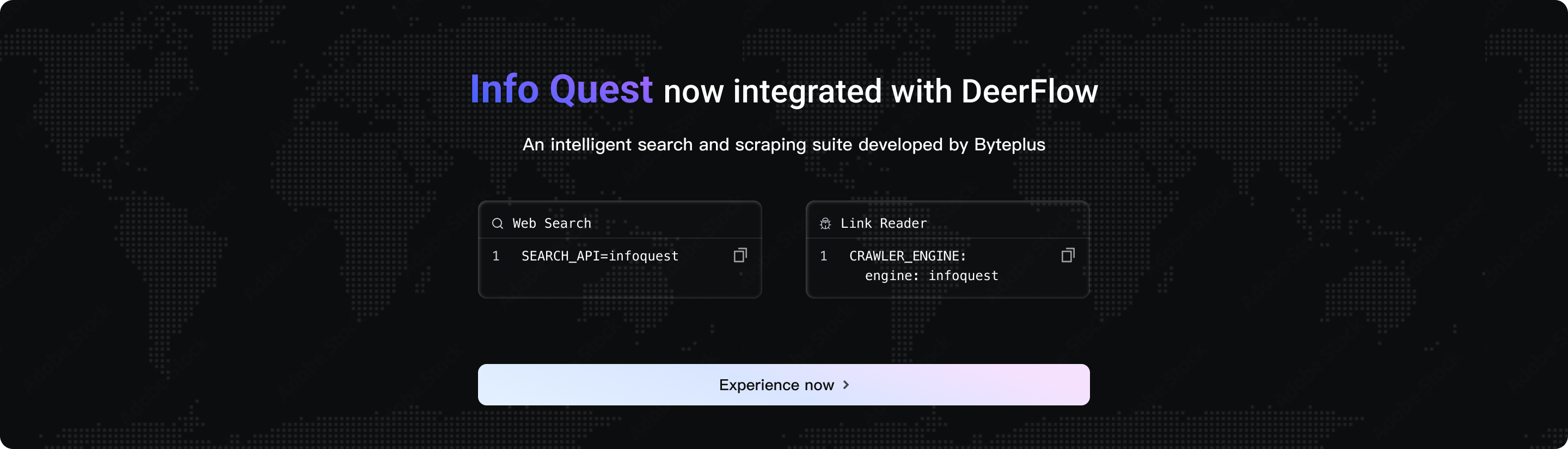
Table of Contents
- 🦌 DeerFlow - 2.0
One-Line Agent Setup
If you use Claude Code, Codex, Cursor, Windsurf, or another coding agent, you can hand it the setup instructions in one sentence:
Help me clone DeerFlow if needed, then bootstrap it for local development by following https://raw.githubusercontent.com/bytedance/deer-flow/main/Install.md
That prompt is intended for coding agents. It tells the agent to clone the repo if needed, choose Docker when available, and stop with the exact next command plus any missing config the user still needs to provide.
Quick Start
Configuration
-
Clone the DeerFlow repository
git clone https://github.com/bytedance/deer-flow.git cd deer-flow -
Run the setup wizard
From the project root directory (
deer-flow/), run:make setupThis launches an interactive wizard that guides you through choosing an LLM provider, optional web search, and execution/safety preferences such as sandbox mode, bash access, and file-write tools. It generates a minimal
config.yamland writes your keys to.env. Takes about 2 minutes.The wizard also lets you configure an optional web search provider, or skip it for now.
Run
make doctorat any time to verify your setup and get actionable fix hints.Advanced / manual configuration: If you prefer to edit
config.yamldirectly, runmake configinstead to copy the full template. Seeconfig.example.yamlfor the complete reference including CLI-backed providers (Codex CLI, Claude Code OAuth), OpenRouter, Responses API, and more.Manual model configuration examples
models: - name: gpt-4o display_name: GPT-4o use: langchain_openai:ChatOpenAI model: gpt-4o api_key: $OPENAI_API_KEY - name: openrouter-gemini-2.5-flash display_name: Gemini 2.5 Flash (OpenRouter) use: langchain_openai:ChatOpenAI model: google/gemini-2.5-flash-preview api_key: $OPENROUTER_API_KEY base_url: https://openrouter.ai/api/v1 - name: gpt-5-responses display_name: GPT-5 (Responses API) use: langchain_openai:ChatOpenAI model: gpt-5 api_key: $OPENAI_API_KEY use_responses_api: true output_version: responses/v1 - name: qwen3-32b-vllm display_name: Qwen3 32B (vLLM) use: deerflow.models.vllm_provider:VllmChatModel model: Qwen/Qwen3-32B api_key: $VLLM_API_KEY base_url: http://localhost:8000/v1 supports_thinking: true when_thinking_enabled: extra_body: chat_template_kwargs: enable_thinking: trueOpenRouter and similar OpenAI-compatible gateways should be configured with
langchain_openai:ChatOpenAIplusbase_url. If you prefer a provider-specific environment variable name, pointapi_keyat that variable explicitly (for exampleapi_key: $OPENROUTER_API_KEY).To route OpenAI models through
/v1/responses, keep usinglangchain_openai:ChatOpenAIand setuse_responses_api: truewithoutput_version: responses/v1.For vLLM 0.19.0, use
deerflow.models.vllm_provider:VllmChatModel. For Qwen-style reasoning models, DeerFlow toggles reasoning withextra_body.chat_template_kwargs.enable_thinkingand preserves vLLM's non-standardreasoningfield across multi-turn tool-call conversations. Legacythinkingconfigs are normalized automatically for backward compatibility. Reasoning models may also require the server to be started with--reasoning-parser .... If your local vLLM deployment accepts any non-empty API key, you can still setVLLM_API_KEYto a placeholder value.CLI-backed provider examples:
models: - name: gpt-5.4 display_name: GPT-5.4 (Codex CLI) use: deerflow.models.openai_codex_provider:CodexChatModel model: gpt-5.4 supports_thinking: true supports_reasoning_effort: true - name: claude-sonnet-4.6 display_name: Claude Sonnet 4.6 (Claude Code OAuth) use: deerflow.models.claude_provider:ClaudeChatModel model: claude-sonnet-4-6 max_tokens: 4096 supports_thinking: true- Codex CLI reads
~/.codex/auth.json - Claude Code accepts
CLAUDE_CODE_OAUTH_TOKEN,ANTHROPIC_AUTH_TOKEN,CLAUDE_CODE_CREDENTIALS_PATH, or~/.claude/.credentials.json - ACP agent entries are separate from model providers — if you configure
acp_agents.codex, point it at a Codex ACP adapter such asnpx -y @zed-industries/codex-acp - On macOS, export Claude Code auth explicitly if needed:
eval "$(python3 scripts/export_claude_code_oauth.py --print-export)"API keys can also be set manually in
.env(recommended) or exported in your shell:OPENAI_API_KEY=your-openai-api-key TAVILY_API_KEY=your-tavily-api-key - Codex CLI reads
Running the Application
Deployment Sizing
Use the table below as a practical starting point when choosing how to run DeerFlow:
| Deployment target | Starting point | Recommended | Notes |
|---|---|---|---|
Local evaluation / make dev |
4 vCPU, 8 GB RAM, 20 GB free SSD | 8 vCPU, 16 GB RAM | Good for one developer or one light session with hosted model APIs. 2 vCPU / 4 GB is usually not enough. |
Docker development / make docker-start |
4 vCPU, 8 GB RAM, 25 GB free SSD | 8 vCPU, 16 GB RAM | Image builds, bind mounts, and sandbox containers need more headroom than pure local dev. |
Long-running server / make up |
8 vCPU, 16 GB RAM, 40 GB free SSD | 16 vCPU, 32 GB RAM | Preferred for shared use, multi-agent runs, report generation, or heavier sandbox workloads. |
- These numbers cover DeerFlow itself. If you also host a local LLM, size that service separately.
- Linux plus Docker is the recommended deployment target for a persistent server. macOS and Windows are best treated as development or evaluation environments.
- If CPU or memory usage stays pinned, reduce concurrent runs first, then move to the next sizing tier.
Option 1: Docker (Recommended)
Development (hot-reload, source mounts):
make docker-init # Pull sandbox image (only once or when image updates)
make docker-start # Start services (auto-detects sandbox mode from config.yaml)
make docker-start starts provisioner only when config.yaml uses provisioner mode (sandbox.use: deerflow.community.aio_sandbox:AioSandboxProvider with provisioner_url).
Docker builds use the upstream uv registry by default. If you need faster mirrors in restricted networks, export UV_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple and NPM_REGISTRY=https://registry.npmmirror.com before running make docker-init or make docker-start.
Backend processes automatically pick up config.yaml changes on the next config access, so model metadata updates do not require a manual restart during development.
Tip
On Linux, if Docker-based commands fail with
permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock, add your user to thedockergroup and re-login before retrying. See CONTRIBUTING.md for the full fix.
Production (builds images locally, mounts runtime config and data):
make up # Build images and start all production services
make down # Stop and remove containers
Note
The LangGraph agent server currently runs via
langgraph dev(the open-source CLI server).
Access: http://localhost:2026
See CONTRIBUTING.md for detailed Docker development guide.
Option 2: Local Development
If you prefer running services locally:
Prerequisite: complete the "Configuration" steps above first (make setup). make dev requires a valid config.yaml in the project root (can be overridden via DEER_FLOW_CONFIG_PATH). Run make doctor to verify your setup before starting.
On Windows, run the local development flow from Git Bash. Native cmd.exe and PowerShell shells are not supported for the bash-based service scripts, and WSL is not guaranteed because some scripts rely on Git for Windows utilities such as cygpath.
-
Check prerequisites:
make check # Verifies Node.js 22+, pnpm, uv, nginx -
Install dependencies:
make install # Install backend + frontend dependencies -
(Optional) Pre-pull sandbox image:
# Recommended if using Docker/Container-based sandbox make setup-sandbox -
(Optional) Load sample memory data for local review:
python scripts/load_memory_sample.pyThis copies the sample fixture into the default local runtime memory file so reviewers can immediately test
Settings > Memory. See backend/docs/MEMORY_SETTINGS_REVIEW.md for the shortest review flow. -
Start services:
make dev -
Access: http://localhost:2026
Startup Modes
DeerFlow supports multiple startup modes across two dimensions:
- Dev / Prod — dev enables hot-reload; prod uses pre-built frontend
- Standard / Gateway — standard uses a separate LangGraph server (4 processes); Gateway mode (experimental) embeds the agent runtime in the Gateway API (3 processes)
| Local Foreground | Local Daemon | Docker Dev | Docker Prod | |
|---|---|---|---|---|
| Dev | ./scripts/serve.sh --devmake dev |
./scripts/serve.sh --dev --daemonmake dev-daemon |
./scripts/docker.sh startmake docker-start |
— |
| Dev + Gateway | ./scripts/serve.sh --dev --gatewaymake dev-pro |
./scripts/serve.sh --dev --gateway --daemonmake dev-daemon-pro |
./scripts/docker.sh start --gatewaymake docker-start-pro |
— |
| Prod | ./scripts/serve.sh --prodmake start |
./scripts/serve.sh --prod --daemonmake start-daemon |
— | ./scripts/deploy.shmake up |
| Prod + Gateway | ./scripts/serve.sh --prod --gatewaymake start-pro |
./scripts/serve.sh --prod --gateway --daemonmake start-daemon-pro |
— | ./scripts/deploy.sh --gatewaymake up-pro |
| Action | Local | Docker Dev | Docker Prod |
|---|---|---|---|
| Stop | ./scripts/serve.sh --stopmake stop |
./scripts/docker.sh stopmake docker-stop |
./scripts/deploy.sh downmake down |
| Restart | ./scripts/serve.sh --restart [flags] |
./scripts/docker.sh restart |
— |
Gateway mode eliminates the LangGraph server process — the Gateway API handles agent execution directly via async tasks, managing its own concurrency.
Why Gateway Mode?
In standard mode, DeerFlow runs a dedicated LangGraph Platform server alongside the Gateway API. This architecture works well but has trade-offs:
| Standard Mode | Gateway Mode | |
|---|---|---|
| Architecture | Gateway (REST API) + LangGraph (agent runtime) | Gateway embeds agent runtime |
| Concurrency | --n-jobs-per-worker per worker (requires license) |
--workers × async tasks (no per-worker cap) |
| Containers / Processes | 4 (frontend, gateway, langgraph, nginx) | 3 (frontend, gateway, nginx) |
| Resource usage | Higher (two Python runtimes) | Lower (single Python runtime) |
| LangGraph Platform license | Required for production images | Not required |
| Cold start | Slower (two services to initialize) | Faster |
Both modes are functionally equivalent — the same agents, tools, and skills work in either mode.
Docker Production Deployment
deploy.sh supports building and starting separately. Images are mode-agnostic — runtime mode is selected at start time:
# One-step (build + start)
deploy.sh # standard mode (default)
deploy.sh --gateway # gateway mode
# Two-step (build once, start with any mode)
deploy.sh build # build all images
deploy.sh start # start in standard mode
deploy.sh start --gateway # start in gateway mode
# Stop
deploy.sh down
Advanced
Sandbox Mode
DeerFlow supports multiple sandbox execution modes:
- Local Execution (runs sandbox code directly on the host machine)
- Docker Execution (runs sandbox code in isolated Docker containers)
- Docker Execution with Kubernetes (runs sandbox code in Kubernetes pods via provisioner service)
For Docker development, service startup follows config.yaml sandbox mode. In Local/Docker modes, provisioner is not started.
See the Sandbox Configuration Guide to configure your preferred mode.
MCP Server
DeerFlow supports configurable MCP servers and skills to extend its capabilities.
For HTTP/SSE MCP servers, OAuth token flows are supported (client_credentials, refresh_token).
See the MCP Server Guide for detailed instructions.
IM Channels
DeerFlow supports receiving tasks from messaging apps. Channels auto-start when configured — no public IP required for any of them.
| Channel | Transport | Difficulty |
|---|---|---|
| Telegram | Bot API (long-polling) | Easy |
| Slack | Socket Mode | Moderate |
| Feishu / Lark | WebSocket | Moderate |
| Tencent iLink (long-polling) | Moderate | |
| WeCom | WebSocket | Moderate |
Configuration in config.yaml:
channels:
# LangGraph Server URL (default: http://localhost:2024)
langgraph_url: http://localhost:2024
# Gateway API URL (default: http://localhost:8001)
gateway_url: http://localhost:8001
# Optional: global session defaults for all mobile channels
session:
assistant_id: lead_agent # or a custom agent name; custom agents are routed via lead_agent + agent_name
config:
recursion_limit: 100
context:
thinking_enabled: true
is_plan_mode: false
subagent_enabled: false
feishu:
enabled: true
app_id: $FEISHU_APP_ID
app_secret: $FEISHU_APP_SECRET
# domain: https://open.feishu.cn # China (default)
# domain: https://open.larksuite.com # International
wecom:
enabled: true
bot_id: $WECOM_BOT_ID
bot_secret: $WECOM_BOT_SECRET
slack:
enabled: true
bot_token: $SLACK_BOT_TOKEN # xoxb-...
app_token: $SLACK_APP_TOKEN # xapp-... (Socket Mode)
allowed_users: [] # empty = allow all
telegram:
enabled: true
bot_token: $TELEGRAM_BOT_TOKEN
allowed_users: [] # empty = allow all
wechat:
enabled: false
bot_token: $WECHAT_BOT_TOKEN
ilink_bot_id: $WECHAT_ILINK_BOT_ID
qrcode_login_enabled: true # optional: allow first-time QR bootstrap when bot_token is absent
allowed_users: [] # empty = allow all
polling_timeout: 35
state_dir: ./.deer-flow/wechat/state
max_inbound_image_bytes: 20971520
max_outbound_image_bytes: 20971520
max_inbound_file_bytes: 52428800
max_outbound_file_bytes: 52428800
# Optional: per-channel / per-user session settings
session:
assistant_id: mobile-agent # custom agent names are also supported here
context:
thinking_enabled: false
users:
"123456789":
assistant_id: vip-agent
config:
recursion_limit: 150
context:
thinking_enabled: true
subagent_enabled: true
Notes:
assistant_id: lead_agentcalls the default LangGraph assistant directly.- If
assistant_idis set to a custom agent name, DeerFlow still routes throughlead_agentand injects that value asagent_name, so the custom agent's SOUL/config takes effect for IM channels.
Set the corresponding API keys in your .env file:
# Telegram
TELEGRAM_BOT_TOKEN=123456789:ABCdefGHIjklMNOpqrSTUvwxYZ
# Slack
SLACK_BOT_TOKEN=xoxb-...
SLACK_APP_TOKEN=xapp-...
# Feishu / Lark
FEISHU_APP_ID=cli_xxxx
FEISHU_APP_SECRET=your_app_secret
# WeChat iLink
WECHAT_BOT_TOKEN=your_ilink_bot_token
WECHAT_ILINK_BOT_ID=your_ilink_bot_id
# WeCom
WECOM_BOT_ID=your_bot_id
WECOM_BOT_SECRET=your_bot_secret
Telegram Setup
- Chat with @BotFather, send
/newbot, and copy the HTTP API token. - Set
TELEGRAM_BOT_TOKENin.envand enable the channel inconfig.yaml.
Slack Setup
- Create a Slack App at api.slack.com/apps → Create New App → From scratch.
- Under OAuth & Permissions, add Bot Token Scopes:
app_mentions:read,chat:write,im:history,im:read,im:write,files:write. - Enable Socket Mode → generate an App-Level Token (
xapp-…) withconnections:writescope. - Under Event Subscriptions, subscribe to bot events:
app_mention,message.im. - Set
SLACK_BOT_TOKENandSLACK_APP_TOKENin.envand enable the channel inconfig.yaml.
Feishu / Lark Setup
- Create an app on Feishu Open Platform → enable Bot capability.
- Add permissions:
im:message,im:message.p2p_msg:readonly,im:resource. - Under Events, subscribe to
im.message.receive_v1and select Long Connection mode. - Copy the App ID and App Secret. Set
FEISHU_APP_IDandFEISHU_APP_SECRETin.envand enable the channel inconfig.yaml.
WeChat Setup
- Enable the
wechatchannel inconfig.yaml. - Either set
WECHAT_BOT_TOKENin.env, or setqrcode_login_enabled: truefor first-time QR bootstrap. - When
bot_tokenis absent and QR bootstrap is enabled, watch backend logs for the QR content returned by iLink and complete the binding flow. - After the QR flow succeeds, DeerFlow persists the acquired token under
state_dirfor later restarts. - For Docker Compose deployments, keep
state_diron a persistent volume so theget_updates_bufcursor and saved auth state survive restarts.
WeCom Setup
- Create a bot on the WeCom AI Bot platform and obtain the
bot_idandbot_secret. - Enable
channels.wecominconfig.yamland fill inbot_id/bot_secret. - Set
WECOM_BOT_IDandWECOM_BOT_SECRETin.env. - Make sure backend dependencies include
wecom-aibot-python-sdk. The channel uses a WebSocket long connection and does not require a public callback URL. - The current integration supports inbound text, image, and file messages. Final images/files generated by the agent are also sent back to the WeCom conversation.
When DeerFlow runs in Docker Compose, IM channels execute inside the gateway container. In that case, do not point channels.langgraph_url or channels.gateway_url at localhost; use container service names such as http://langgraph:2024 and http://gateway:8001, or set DEER_FLOW_CHANNELS_LANGGRAPH_URL and DEER_FLOW_CHANNELS_GATEWAY_URL.
Commands
Once a channel is connected, you can interact with DeerFlow directly from the chat:
| Command | Description |
|---|---|
/new |
Start a new conversation |
/status |
Show current thread info |
/models |
List available models |
/memory |
View memory |
/help |
Show help |
Messages without a command prefix are treated as regular chat — DeerFlow creates a thread and responds conversationally.
LangSmith Tracing
DeerFlow has built-in LangSmith integration for observability. When enabled, all LLM calls, agent runs, and tool executions are traced and visible in the LangSmith dashboard.
Add the following to your .env file:
LANGSMITH_TRACING=true
LANGSMITH_ENDPOINT=https://api.smith.langchain.com
LANGSMITH_API_KEY=lsv2_pt_xxxxxxxxxxxxxxxx
LANGSMITH_PROJECT=xxx
Langfuse Tracing
DeerFlow also supports Langfuse observability for LangChain-compatible runs.
Add the following to your .env file:
LANGFUSE_TRACING=true
LANGFUSE_PUBLIC_KEY=pk-lf-xxxxxxxxxxxxxxxx
LANGFUSE_SECRET_KEY=sk-lf-xxxxxxxxxxxxxxxx
LANGFUSE_BASE_URL=https://cloud.langfuse.com
If you are using a self-hosted Langfuse instance, set LANGFUSE_BASE_URL to your deployment URL.
Using Both Providers
If both LangSmith and Langfuse are enabled, DeerFlow attaches both tracing callbacks and reports the same model activity to both systems.
If a provider is explicitly enabled but missing required credentials, or if its callback fails to initialize, DeerFlow fails fast when tracing is initialized during model creation and the error message names the provider that caused the failure.
For Docker deployments, tracing is disabled by default. Set LANGSMITH_TRACING=true and LANGSMITH_API_KEY in your .env to enable it.
From Deep Research to Super Agent Harness
DeerFlow started as a Deep Research framework — and the community ran with it. Since launch, developers have pushed it far beyond research: building data pipelines, generating slide decks, spinning up dashboards, automating content workflows. Things we never anticipated.
That told us something important: DeerFlow wasn't just a research tool. It was a harness — a runtime that gives agents the infrastructure to actually get work done.
So we rebuilt it from scratch.
DeerFlow 2.0 is no longer a framework you wire together. It's a super agent harness — batteries included, fully extensible. Built on LangGraph and LangChain, it ships with everything an agent needs out of the box: a filesystem, memory, skills, sandbox-aware execution, and the ability to plan and spawn sub-agents for complex, multi-step tasks.
Use it as-is. Or tear it apart and make it yours.
Core Features
Skills & Tools
Skills are what make DeerFlow do almost anything.
A standard Agent Skill is a structured capability module — a Markdown file that defines a workflow, best practices, and references to supporting resources. DeerFlow ships with built-in skills for research, report generation, slide creation, web pages, image and video generation, and more. But the real power is extensibility: add your own skills, replace the built-in ones, or combine them into compound workflows.
Skills are loaded progressively — only when the task needs them, not all at once. This keeps the context window lean and makes DeerFlow work well even with token-sensitive models.
When you install .skill archives through the Gateway, DeerFlow accepts standard optional frontmatter metadata such as version, author, and compatibility instead of rejecting otherwise valid external skills.
Tools follow the same philosophy. DeerFlow comes with a core toolset — web search, web fetch, file operations, bash execution — and supports custom tools via MCP servers and Python functions. Swap anything. Add anything.
Gateway-generated follow-up suggestions now normalize both plain-string model output and block/list-style rich content before parsing the JSON array response, so provider-specific content wrappers do not silently drop suggestions.
# Paths inside the sandbox container
/mnt/skills/public
├── research/SKILL.md
├── report-generation/SKILL.md
├── slide-creation/SKILL.md
├── web-page/SKILL.md
└── image-generation/SKILL.md
/mnt/skills/custom
└── your-custom-skill/SKILL.md ← yours
Claude Code Integration
The claude-to-deerflow skill lets you interact with a running DeerFlow instance directly from Claude Code. Send research tasks, check status, manage threads — all without leaving the terminal.
Install the skill:
npx skills add https://github.com/bytedance/deer-flow --skill claude-to-deerflow
Then make sure DeerFlow is running (default at http://localhost:2026) and use the /claude-to-deerflow command in Claude Code.
What you can do:
- Send messages to DeerFlow and get streaming responses
- Choose execution modes: flash (fast), standard, pro (planning), ultra (sub-agents)
- Check DeerFlow health, list models/skills/agents
- Manage threads and conversation history
- Upload files for analysis
Environment variables (optional, for custom endpoints):
DEERFLOW_URL=http://localhost:2026 # Unified proxy base URL
DEERFLOW_GATEWAY_URL=http://localhost:2026 # Gateway API
DEERFLOW_LANGGRAPH_URL=http://localhost:2026/api/langgraph # LangGraph API
See skills/public/claude-to-deerflow/SKILL.md for the full API reference.
Sub-Agents
Complex tasks rarely fit in a single pass. DeerFlow decomposes them.
The lead agent can spawn sub-agents on the fly — each with its own scoped context, tools, and termination conditions. Sub-agents run in parallel when possible, report back structured results, and the lead agent synthesizes everything into a coherent output.
This is how DeerFlow handles tasks that take minutes to hours: a research task might fan out into a dozen sub-agents, each exploring a different angle, then converge into a single report — or a website — or a slide deck with generated visuals. One harness, many hands.
Sandbox & File System
DeerFlow doesn't just talk about doing things. It has its own computer.
Each task gets its own execution environment with a full filesystem view — skills, workspace, uploads, outputs. The agent reads, writes, and edits files. It can view images and, when configured safely, execute shell commands.
With AioSandboxProvider, shell execution runs inside isolated containers. With LocalSandboxProvider, file tools still map to per-thread directories on the host, but host bash is disabled by default because it is not a secure isolation boundary. Re-enable host bash only for fully trusted local workflows.
This is the difference between a chatbot with tool access and an agent with an actual execution environment.
# Paths inside the sandbox container
/mnt/user-data/
├── uploads/ ← your files
├── workspace/ ← agents' working directory
└── outputs/ ← final deliverables
Context Engineering
Isolated Sub-Agent Context: Each sub-agent runs in its own isolated context. This means that the sub-agent will not be able to see the context of the main agent or other sub-agents. This is important to ensure that the sub-agent is able to focus on the task at hand and not be distracted by the context of the main agent or other sub-agents.
Summarization: Within a session, DeerFlow manages context aggressively — summarizing completed sub-tasks, offloading intermediate results to the filesystem, compressing what's no longer immediately relevant. This lets it stay sharp across long, multi-step tasks without blowing the context window.
Long-Term Memory
Most agents forget everything the moment a conversation ends. DeerFlow remembers.
Across sessions, DeerFlow builds a persistent memory of your profile, preferences, and accumulated knowledge. The more you use it, the better it knows you — your writing style, your technical stack, your recurring workflows. Memory is stored locally and stays under your control.
Memory updates now skip duplicate fact entries at apply time, so repeated preferences and context do not accumulate endlessly across sessions.
Recommended Models
DeerFlow is model-agnostic — it works with any LLM that implements the OpenAI-compatible API. That said, it performs best with models that support:
- Long context windows (100k+ tokens) for deep research and multi-step tasks
- Reasoning capabilities for adaptive planning and complex decomposition
- Multimodal inputs for image understanding and video comprehension
- Strong tool-use for reliable function calling and structured outputs
Embedded Python Client
DeerFlow can be used as an embedded Python library without running the full HTTP services. The DeerFlowClient provides direct in-process access to all agent and Gateway capabilities, returning the same response schemas as the HTTP Gateway API. The HTTP Gateway also exposes DELETE /api/threads/{thread_id} to remove DeerFlow-managed local thread data after the LangGraph thread itself has been deleted:
from deerflow.client import DeerFlowClient
client = DeerFlowClient()
# Chat
response = client.chat("Analyze this paper for me", thread_id="my-thread")
# Streaming (LangGraph SSE protocol: values, messages-tuple, end)
for event in client.stream("hello"):
if event.type == "messages-tuple" and event.data.get("type") == "ai":
print(event.data["content"])
# Configuration & management — returns Gateway-aligned dicts
models = client.list_models() # {"models": [...]}
skills = client.list_skills() # {"skills": [...]}
client.update_skill("web-search", enabled=True)
client.upload_files("thread-1", ["./report.pdf"]) # {"success": True, "files": [...]}
All dict-returning methods are validated against Gateway Pydantic response models in CI (TestGatewayConformance), ensuring the embedded client stays in sync with the HTTP API schemas. See backend/packages/harness/deerflow/client.py for full API documentation.
Documentation
- Contributing Guide - Development environment setup and workflow
- Configuration Guide - Setup and configuration instructions
- Architecture Overview - Technical architecture details
- Backend Architecture - Backend architecture and API reference
⚠️ Security Notice
Improper Deployment May Introduce Security Risks
DeerFlow has key high-privilege capabilities including system command execution, resource operations, and business logic invocation, and is designed by default to be deployed in a local trusted environment (accessible only via the 127.0.0.1 loopback interface). If you deploy the agent in untrusted environments — such as LAN networks, public cloud servers, or other multi-endpoint accessible environments — without strict security measures, it may introduce security risks, including:
- Unauthorized illegal invocation: Agent functionality could be discovered by unauthorized third parties or malicious internet scanners, triggering bulk unauthorized requests that execute high-risk operations such as system commands and file read/write, potentially causing serious security consequences.
- Compliance and legal risks: If the agent is illegally invoked to conduct cyberattacks, data theft, or other illegal activities, it may result in legal liability and compliance risks.
Security Recommendations
Note: We strongly recommend deploying DeerFlow in a local trusted network environment. If you need cross-device or cross-network deployment, you must implement strict security measures, such as:
- IP allowlist: Use
iptables, or deploy hardware firewalls / switches with Access Control Lists (ACL), to configure IP allowlist rules and deny access from all other IP addresses. - Authentication gateway: Configure a reverse proxy (e.g., nginx) and enable strong pre-authentication, blocking any unauthenticated access.
- Network isolation: Where possible, place the agent and trusted devices in the same dedicated VLAN, isolated from other network devices.
- Stay updated: Continue to follow DeerFlow's security feature updates.
Contributing
We welcome contributions! Please see CONTRIBUTING.md for development setup, workflow, and guidelines.
Regression coverage includes Docker sandbox mode detection and provisioner kubeconfig-path handling tests in backend/tests/.
Gateway artifact serving now forces active web content types (text/html, application/xhtml+xml, image/svg+xml) to download as attachments instead of inline rendering, reducing XSS risk for generated artifacts.
License
This project is open source and available under the MIT License.
Acknowledgments
DeerFlow is built upon the incredible work of the open-source community. We are deeply grateful to all the projects and contributors whose efforts have made DeerFlow possible. Truly, we stand on the shoulders of giants.
We would like to extend our sincere appreciation to the following projects for their invaluable contributions:
- LangChain: Their exceptional framework powers our LLM interactions and chains, enabling seamless integration and functionality.
- LangGraph: Their innovative approach to multi-agent orchestration has been instrumental in enabling DeerFlow's sophisticated workflows.
These projects exemplify the transformative power of open-source collaboration, and we are proud to build upon their foundations.
Key Contributors
A heartfelt thank you goes out to the core authors of DeerFlow, whose vision, passion, and dedication have brought this project to life:
Your unwavering commitment and expertise have been the driving force behind DeerFlow's success. We are honored to have you at the helm of this journey.